

With the current media popularity of Chat GPT this is an opportunity to also talk about GIVE HER, another artificial intelligence also designed by Open AI ! And more generally image-generating AIs. Where ChatGPT is able to generate written text with disconcerting ease, DALL-E and its ilk have been trained to create images from a simple written request from the user.
Let's take a look at how they work, their capabilities, but also their limits with this comparative article of image-creating AIs.
But by the way, how does an AI work?
A very good question to which it may be interesting to come back quickly, especially since we did not address it in our previous article about ChatGPT. When you hear "Artificial Intelligence" it's hard not to have in mind these kinds of humanoid robots as we have seen them in the movies. This is what the AIs themselves generate when they are asked for an image corresponding to the search for these keywords, such as the introductory image of this article.

Yet in reality, many of the existing AIs have no physical envelope. Indeed, most of the time, it is computer programs based on specific algorithms that have been trained by humans to perform certain more or less complex tasks.
Image generation is a task that can be assigned to one (or more) AIs! To learn more about the methods of creating images by AI, do not hesitate to watch the following video:
Let's generate our first images with artificial intelligence
To do this, nothing could be simpler at first sight, since all you have to do is describe textually to the AI the image you want to obtain. For this article we decided to compare the images given by three AI generators:
- GIVE HER
- stable diffusion
- Canva (Text to Image)
Of course, there are others that you should not hesitate to test as well. Here is one non-exhaustive list.
If you're a little creative, we're sure you'll find plenty of ideas for images to generate. But for those for whom it would be a little more complex it is possible to ask… ChatGPT for a little help. Yes, we used an AI to use another AI…

Of course, as an image generation model, DALL-E can create a wide variety of images. Here are some ideas for images you could generate with DALL-E:
- Fantasy Animals: Ask DALL-E to generate images of imaginary animals, like a dragon with butterfly wings or a snake with legs.
- Strange Foods: Ask DALL-E to generate images of unusual foods, like a chocolate pizza or a burger with slices of watermelon.
- Unusual clothing: Ask DALL-E to generate images of strange clothing, such as an Eiffel Tower-shaped hat or shoes with wings.
- Imaginary Landscapes: Ask DALL-E to generate images of fantasy landscapes, such as a city floating in the clouds or a forest of giant mushrooms.
- Hybrid objects: Ask DALL-E to generate images of objects that are a mix of two different things, like a bed that looks like a hammock or a car with bird wings.
- Celebrity Portraits: Ask DALL-E to generate images of celebrity portraits that don't exist, such as an alternate version of Marilyn Monroe with tattoos.
- Futuristic cars: Ask DALL-E to generate images of futuristic cars, such as a car that can transform into an airplane or a car that can fly.
- Fantasy Architecture: Ask DALL-E to generate images of fantasy architecture, such as a dragon-shaped skyscraper or a house that looks like a tree.
These ideas are just suggestions to give you an idea of what DALL-E can do. There are thousands of other image ideas you could generate with this AI template.
Each AI has its own style
With this list, let's see together how to generate our images, and which of the different software chosen does the best.
For our first image we chose to represent the dragon with butterfly wings. To add some context, we're also asking for this to be depicted in "a fairy tale fantasy forest." Depending on the IAs, the language of the request can impact the result. So we quickly found that for DALL-E and Stable Diffusion English was the language giving the best results. Conversely, Canva's text to image application generally works better in French.
1. DALL-E generated images of a butterfly-winged dragon




2. Dragons generated by Stable Diffusion




3. And finally the one we chose to keep for the Canva tool

The first thing we can see very quickly: for the same request, each AI has its own style!
- DALL-E has an "imaginative" side, although the "fairy tale" forest is a bit dark for fairy, the butterfly wings are well represented and neat. It's in style Digital art.
- At Stable Diffusion the style is more "joyful", a bit childish. We imagine very well these images illustrating a story for children. Here the dragons are clearly visible and recall China, of which it is the emblem. On the other hand, the AI completely obscured the butterfly wings and chose the easy solution by making real butterflies appear alongside our dragons.
- Finally for the Canva tool, we selected the only image corresponding to our request from the selection. However, the two elements (dragon and wings are present here). While all of the images are in-theme and actionable, Canva does best in faithfully executing the request and therefore earns a first point here.
What are the artistic style possibilities of the requested image?
If no details about the art style are requested, then the AIs will choose them for you as in the example of the dragons.
Nevertheless, on Dall-e for example, it is possible to define the following styles:
- Oil painting : Dall-e can generate oil paintings from a description of the colors and textures you want to see in the painting.
- Photography : Dall-e can generate photos based on the colors, textures and details you want to see in the photo.
- Digital art : Dall-e can produce digital artwork from a pre-designed template or from a description of the colors and details you want to see in the artwork.
- Abstract art : Dall-e can produce abstract works based on the movements, colors and shapes you want to see in the work.
- Drawing : Dall-e can generate designs based on the colors and shapes you want to see in the design.
- Vector art : Dall-e can generate vector images from a predefined template or from a description of the colors and details you want to see in the image.
The examples of Dragon were a priori made in Digital Art style. The style will strongly influence the final generated image.
Stronger still, it is possible to request styles of some famous artist. So we generated a chat in the style Picasso, Van Gogh and Dali ! And the results are…quite stunning!
Our AI-drawn cat in the styles of 3 great painting masters
- Picasso style cat

- Van Gogh style cat
- Dali style cat
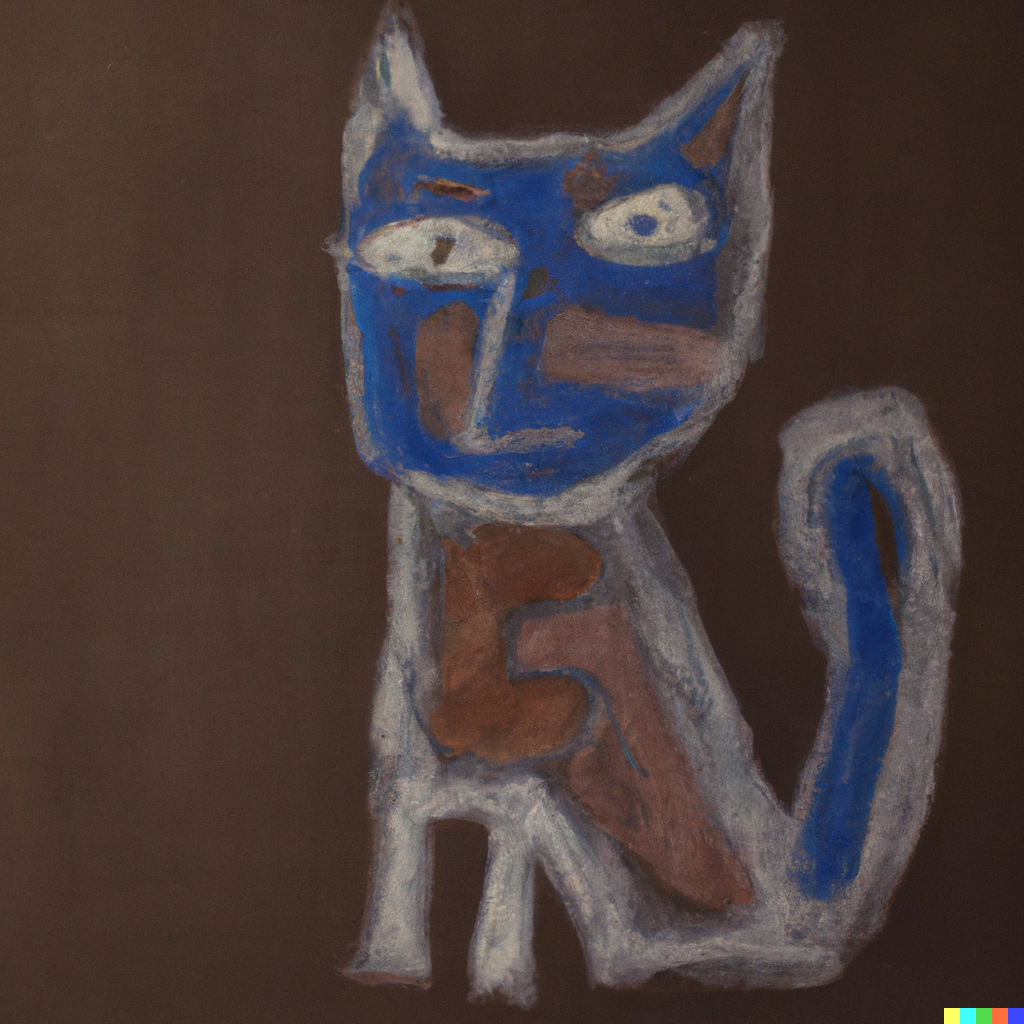


Better, we then asked for a “ Cat in Picasso and Dali and Van Gogh style and we got this:

We have also requested "Pig in the Picasso Style" and the result was equally, if not more, impressive…

AIs are likely to (will) revolutionize the field of Art and the Internet in the coming years, which is already the case with speculative NFTs.
We understand the distrust of professionals of art vis-à-vis these artistic AIs, their fears are the same as those of publishing and literary creation vis-à-vis chatbots like ChatGPT! They are right, all these fears are, in our opinion, justified!
What are the different methods to request the creation of an image with Dall-e?
Several methods can be used to indicate the creation of an image with Dalle-e, including graphic methods for a faster result corresponding to your needs:
- Generating images from keywords : you can enter a keyword and Dall-e will produce an image based on the keywords you entered.
- Generating images from sentences : you can enter a complete sentence and Dall-e will produce an image based on the sentence you have entered.
- Generating images from image descriptions : Dall-e can generate images from a detailed description of the colors, shapes and objects you want to see in the image.
- Generating images from scenes : Dall-e can generate 3D images from a complete description of a scene.
- Generating images from patterns : Dall-e can generate images from patterns you input.
- Generating Images from Templates : you can provide Dall-e with a predefined template and it will produce images based on the template you provided.
- Generation of images from animated sequences : Dall-e can generate animated sequences from the description of movements, colors and sounds that you want to see in the sequence.
Realistic but improbable images
We then asked our AI image generators to draw us a salad with eyes : two elements which at first glance do not go together. Yet on this stage, our 3 generators came through without any apparent difficulty.
1. The four images, of a salad with eyes, proposed by DALL-E




2. The two images corresponding to our request generated by Stable Diffusion

3. And the two corresponding images for the Canva tool


Here again, each image has its own style, but what is particularly striking is the realism of the different images: the AIs have used the photographic style.
We recognize foods particularly well, to the point that we might want to reproduce the different ideas proposed in the kitchen. If Canva stands out for its originality by nevertheless offering an image with "emoticon" inspirations, it is here DALL-E which wins the point with four different images and all in the requested theme.
Among the flops of Stable Diffusion, one of the images is still worth coming back to
 Indeed, on this image eliminated because it does not include eyes, we see on the other hand the effort of realism of the AI in the representation of the work plan.
Indeed, on this image eliminated because it does not include eyes, we see on the other hand the effort of realism of the AI in the representation of the work plan.
Our AIs are indeed able to link the word “salad” to the corresponding environment. This was already the case on the images above with the representation of plates, forks and other elements related to the culinary field.
Flops that still remain regular
Despite their general efficiency, our AIs still generate a good amount mediocre, erroneous images sees totally out of step with demand. This was the case for our Eiffel Tower shaped hat.
DALL-E wins the point with its only image approaching our request: a white hat, surmounted by a miniature Tower that we would imagine perfectly on the head of Geneviève de Fontenay !

Apart from this little giggle offered by the AI of Open AI, the other images were either too realistic, simply representing one of the elements while obscuring the other:

 On the first image Stable Diffusion represents the Tower, while on the second DALL-E chose to send us a stack of hats, also obscuring the second part of our request.
On the first image Stable Diffusion represents the Tower, while on the second DALL-E chose to send us a stack of hats, also obscuring the second part of our request.
Either they had an erroneous understanding of the request as in these two images in which DALL-E rather represents souvenir figurines of the Eiffel Tower:
 Finally, some images are sometimes completely offbeat, as was the case for this image supposed to represent a "person from the imagination of IA Stable Diffusion" who then chose to spontaneously add a quote in an unknown language...close from English…
Finally, some images are sometimes completely offbeat, as was the case for this image supposed to represent a "person from the imagination of IA Stable Diffusion" who then chose to spontaneously add a quote in an unknown language...close from English…

A sensitivity that sometimes varies word by word
By carrying out the tests, we quickly realize that it is sometimes enough for our AI to correct the situation in the event of unsatisfactory results. So when we ask our AI for the first time "a floating city in a cloudy sky" by selecting the best image for each of them, we get the following result:


 Respectively from top to bottom, the results of Stable Diffusion, DALL-E and Canva
Respectively from top to bottom, the results of Stable Diffusion, DALL-E and Canva
Very nice images, but which do not really reflect the "unreal" connotation of our request understood by humans but apparently not by our generators. All it takes is a subtle change in demand to get completely different results.
So with the sentence "a fantastic city floating in a cloudy sky" we get this time:
1. Much more imaginative imagery from DALL-E




2. Very pretty fantastic cities from Stable Diffusion which however completely omits the “floating in a cloudy sky” part
3. Some scenes that could be taken from a video game (Minecraft or Lego Worlds for example) by Canva










Here we can award a point for DALL-E and Canva who both managed, through one or other of our requests, to make our city float in the clouds.
But then, what future for the generation of images?
Faced with a solution that works quite well overall, one wonders what the future uses of the generation of images by artificial intelligence might be. Of course it is tempting to quote here the creation of fails on the internet, do not hesitate to come post on our forum ones you might have already come across online.
But we can also imagine more serious uses. Thus the results obtained by asking the Canva tool to create an image of a “tree that is in fact a house” could easily give ideas to an architect responsible for creating habitats that can blend into nature!




But then, which of our 3 image generators is doing the best?
For the tree which would also be a house, we easily give a point to each tool!


 Examples of images proposed respectively by DALL-E, Stable Diffusion then the Canva tool
Examples of images proposed respectively by DALL-E, Stable Diffusion then the Canva tool
The car with bird wings had challenged all of our AIs, but the car that can fly allowed Canva and Stable Diffusion to stand out with some pretty realistic futuristic renderings:

 Respectively Stable Diffusion on top and Canva on bottom.
Respectively Stable Diffusion on top and Canva on bottom.
Finally DALL-E has shown itself to be quite efficient with its dragon shaped building (which remains under construction, however), and Canva was able to best meet the request for a portrait that we had modified somewhat by replacing the celebrity with "a person from the imagination of the AI".



In the final count, these are therefore DALL-E and Canva's tool which respectively win 5 points each.
They are generally able to provide results in line with a majority of user requests.
Canva stands out for its realism while DALL-E seems more relevant as soon as the request requires imagination or the field of painting.
However, despite only 2 points, Stable Diffusion does not fail in the image quality it is able to provide! The downside lies in his understanding of user requests since he often tends to remain very down to earth. However, it remains very interesting to discover as well.
Anyway, we can expect in the years to come, to see artificial intelligence revolutionize many sectors of activity. And certainly faster than some think since books written, in part or in full, by AIs are already on sale on Amazon…This short video report from BFMTV talked about it a few days ago: